
Real-Time Does Not Eliminate the Need for Control
One of the most common misconceptions around SAP S/4HANA Group Reporting is the idea that “real-time” data eliminates the need for control.
It does not.
Real-time processing changes when data becomes available. It does not change the need to validate, structure, and formally accept that data before it is used for consolidation.
This is precisely why Group Reporting includes a release process.
At first glance, the release step can feel redundant. If data is already posted and available in real time, why introduce an additional layer before consolidation?
Because availability is not the same as reliability.
Financial data flows from multiple entities, systems, and processes. It is subject to late adjustments, incomplete postings, intercompany mismatches, and local corrections. Without a controlled checkpoint, consolidation would operate on a constantly shifting dataset.
The release process creates that checkpoint.
It defines the moment when data transitions from “available” to “approved for consolidation.” This distinction is critical in a real-time environment, where data is continuously changing. Without it, there is no stable foundation for currency translation, eliminations, or investment consolidation.
In that sense, real-time increases the need for control rather than reducing it.
The faster data moves, the more important it becomes to establish clear boundaries around when that data is considered complete.
This is not a technical constraint. It is a financial control principle.
The role of the release process is not to slow down the close. It is to protect its integrity.
Real-time systems enable earlier visibility and faster issue identification. They allow teams to prepare data continuously rather than waiting for period-end. But they do not remove the need for a defined cut-off — a point at which the data is locked for consolidation purposes.
Organizations that misunderstand this often attempt to bypass or minimize the release step. The result is typically inconsistent consolidation outcomes, reconciliation issues, and a loss of trust in reported numbers.
The architecture is intentional.
Real-time supports the process.
Control defines the outcome.
Group Reporting Is Misunderstood
SAP’s naming of “Group Reporting” is misleading.
Despite the label, Group Reporting is not primarily a reporting solution. It is a consolidation engine — designed to structure, transform, and control financial data at the group level.
At its core, Group Reporting exists to execute the corporate close. This includes currency translation, intercompany eliminations, investment consolidation, and validation of financial data across entities. These processes are not analytical in nature — they are structural. They define how financial information is standardized, adjusted, and ultimately made consistent across the organization.
This distinction matters.
Many finance teams approach Group Reporting with the expectation that it will also serve as the primary reporting and analytics layer. This is where misalignment begins.
While SAP provides Fiori-based reports as part of the standard solution, these are not the primary strength of the platform. They require adaptation to client-specific master data and offer limited flexibility in formatting and presentation. As a result, most organizations continue to rely on downstream tools — often Excel or dedicated analytics platforms — to produce final outputs for management, boards, and external stakeholders.
This is not a limitation of the system. It reflects a separation of concerns.
Group Reporting is responsible for producing a controlled, consolidated dataset. Analytics and reporting sit on top of that dataset — not within the consolidation engine itself.
The same pattern applies to integrations with tools such as SAP Analytics Cloud (SAC). These solutions extend the reporting layer, but they operate on the foundation created by Group Reporting. They do not replace its role.
The implication is straightforward: evaluating Group Reporting as a reporting tool misses its purpose.
It is not designed to visualize data.
It is designed to make the data correct.
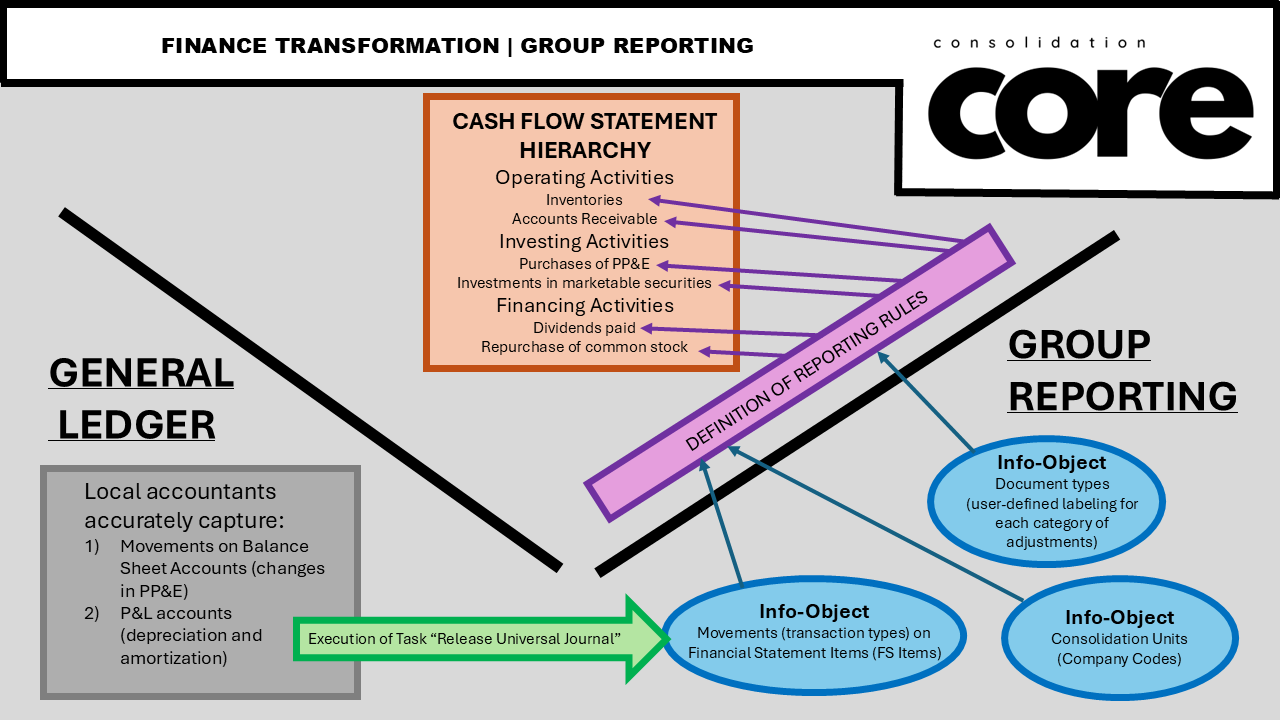
Cash Flow Is Not a Report — It’s a Data Model Problem
Cash flow is not a reporting output — it is a direct reflection of how financial data is structured at the source.
The cash flow statement is often treated as a reporting requirement. In reality, it is a structural test of the underlying financial data model.
Unlike the balance sheet or P&L, cash flow is not a static view. It is entirely driven by movements. Every line in the statement depends on how changes in financial positions are captured, classified, and aggregated across the organization.
This is where most implementations break down.
Organizations typically operate across multiple workstreams — Treasury, Tax, Corporate Accounting, Capital Structure — each contributing pieces of the overall picture. While this complexity is expected, the assumption that a system can reconstruct cash flow from aggregated balances is fundamentally flawed.
No system, including SAP S/4HANA for Group Reporting, can infer how amounts should be allocated across operating, investing, and financing activities without structured input. Data integrity is not a feature — it is a discipline.
In a well-designed model, movements are captured correctly at the source in the general ledger. These movements flow into Group Reporting, where adjustments can be made in a controlled and traceable way using dedicated document types and authorization structures. At any point, the origin of an adjustment — including user, workstream, and timestamp — remains transparent.
The implication is straightforward: cash flow is not built at the reporting layer. It is embedded in how financial data is structured from the beginning.
This also explains why “out-of-the-box” solutions rarely meet expectations. No two organizations share the same data model, master data, or internal reporting logic. A pre-delivered report cannot account for these differences.
Even where standard reports exist, such as SAP’s Fiori-based cash flow statement, they are often insufficient for practical use. Finance teams continue to rely on Excel-based outputs for flexibility, validation, and integration into established reporting formats. Formatting is not a cosmetic concern — it is part of the reporting process itself.
Group Reporting does provide a powerful framework to support cash flow design, particularly through reporting rules. These allow for precise definitions of how data is aggregated using dimensions such as movements, document types, consolidation units, and sign logic. But these rules do not replace the need for a coherent data model — they depend on it.
If the cash flow statement requires manual correction, the issue is not the report.
It is the model.